
Azure Databricks – Data Intelligence Platform

Azure Databricks tarjoaa kokonaisvaltaista analytiikan kehittäjäkokemusta
Databricks kehittää analytiikan kokonaispalvelua, jossa yhdistyy erilaisia datankäsittelyn moottoreita yhdessä avointeiden tiedostomuotojen kanssa Object Storage – tyyppisissä tiedontallennusratkaisuissa, joista Azure Storage on yksi esimerkki. Spark on ollut pitkään keskeinen datankäsittelyn moottori Databricksissa ja yhtiön perustajilla on ollut suuri rooli Sparkin kehityksessä. Databricks palveluna on käytettävissä kaikissa kolmessa suuressa globaalissa pilvipalvelussa. Tässä kirjoituksessa käsitellään nimenomaan Azure Databricksiä ja sen ominaisuuksia kehittäjän näkökulmasta.
Azure Databricksin palveluita voivat käyttää Data Engineer, Data Scientist, Machine Learning Engineer ja Data Analyst – rooleissa työskentelevät kehittäjät erityyppisissä organisaatioissa.
Lyhyenä yhteenvetona voidaan todeta, että Azure Databricks on Databricksin Azuressa tarjoama kokonaisvaltainen analytiikkapalvelu.
Datan käsittelyn moottorit
Eräs keskeisiä moderneja datan käsittelyn moottoreita on Spark, käyttäjän ei tarvitse itse hallinnoida laskentaklustereita, vaan ne ovat Databricksin Microsoftin Azuressa operoimia. Spark itsessään on massiivisen hajautetun rinnakkaislaskennan työkuormiin tarkoitettu.
Azure Databricksin Serverless SQL - ominaisuudet mahdollistavat tietovarastoinnin ja analyyttiset SQL – kyselyt Azure Storageen tallennettaviin avoimen tiedostoformaatin tietorakenteisiin. Tällä tavalla Databricks Azuressa tarjoaa suoraan käytettäväksi tarkoitukseensa optimoituja tietovarastoinnin klustereita.
Tapahtumavirta / telemetriadatan analysointiin on tarjolla Delta Live Tables – ominaisuus, joka mahdollistaa helpohkon tavan määritellä datan käsittelyn automaattisia tietovirtoja. Tällöin ei luoda käsittelyyn Spark – tehtäviä, joita suoritetaan vaan enemmänkin määritellään objekteja jotka toteuttavat datan käsittelyä.
Azure Databricksin ja toisaalta yleisesti Databricksin datan käsittelyn moottorit tukevat hyvin monenlaisia analytiikan ja koneoppimisen / tekoälyn hyödyntämisen käyttötapauksia.
Avoimet tiedostoformaatit ytimessä
Azure Databricksissä datan pysyväistallennus ja datan käsittelyn erilaiset tarpeen mukaiset moottorit ovat aidosti erotettu toisistaan, tämä on mahdollista määrittämällä sopivalla tavalla Azure Storagessa sijaitsevat hakemistorakenteet.
Databricksin käyttämä Delta Lake – tallennuskerros hyödyntää avoimen lähdekoodin Delta Tables – ominaisuutta, joka on laajennos pitkään käytössä olleiden parquet – tiedostojen päällä.
Delta – taulut mahdollistavat myös tietynlaisen versiohistoriaan palaamisen.
Koneoppiminen ja MLOps Azure Databricksissa
Azure Databricks tarjoaa MLflown toiminnallisuuksien osalta seuraavanlaisia osioita koneoppimismallien kehittämiseen sekä elinkaarenhallintaan.
- Koneoppimismallien kehitysvaiheen tulosten seuraaminen ja tallennus, Experiments
- Mallien ylläpidon, Models
- Mallien hyödyntämisprosessia käytettävien syötteiden eli ominaisuuksien hallinnan, Feature Store Unity Catalogin kautta
- Mallien hyödyntämisen eli scoring – operaatiot
Tarkemmin käytettävissä olevat ominaisuudet koneoppimismallien kehittämiseen ja elinkaarenhallintaan on kuvattu tässä.
Tietovirtojen ja tehtävien orkesterointi
Azure Databricksissa on mahdollista hyödyntää sen omia toiminnallisuuksia erilaisten työnkulkujen orkesterointiin, tämän lisäksi vaikkapa yksittäisiä Notebookeja ja niiden välisiä riippuvuuksia voidaan hallinnoida Azure Data Factoryä tai muuta vastaavaa palvelua käyttäen. Tai hyödyntää suoraan Jobs API – toiminnallisuutta.
Tarkemmin asia on kuvattu tässä.
Azure Databricks ja Unity Catalog
Unity Catalog tarjoaa keskitettyä käyttöoikeuksien, auditoinnin ja data discovery toiminnallisuuksia määriteltyjen Azure Databricksin työtilojen suhteen.
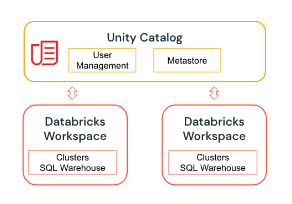
Unity Catalogin metastoren avulla hallitaan metadataa liittyen catalogeihin, skeemoihin ja skeeman alla oleviin objekteihin kuten tauluihin liittyen.
Unity Catalogin kautta voidaan myös hallita keskitetysti credentiaaleja ja ulkoisia sijainteja joihin pääsy määritellään Unity Catalogissa.
Azure Databricksin käyttökustannusten muodostuminen
Azure Databricksissa kustannusten muodostumiseen vaikuttaa haluttu Databricksin tilin taso sekä eräänlainen laskennallinen käyttökustannus klusterien suorituskykytason sekä eräiden lisäominaisuuksien mukaisesti. Kustannukset muodostuvat siis laskentakapasiteetin käytöstä.
Tämän lisäksi Azure Storagessa käytetty tallennustila sekä joissain tapauksissa alueiden välinen tiedonsiirto tuottavat kustannuksia.
Miten lähteä liikkeelle Azure Databricksin kanssa?
Me Ready Solutions Oy olemme tehneet vuosia töitä asiakkaidemme Microsoftin Azuren data-palveluiden parissa, tiedämme erilaiset tarpeet analytiikalle ja tietolähteiden kirjon. Ota yhteyttä alla olevalla lomakkeella ja keskustellaan yhdessä siitä, miten Azure Databricks voisi auttaa organisaatiotasi yhtenäisen analytiikkaympäristön mahdollistajana!
